
Am 17. August 2023 findet der diesjährige »Digital Demo Day 2023« in Düsseldorf statt – nach den Veranstaltern die größte B2B Start-up Expo & Konferenz in Deutschland. Plus: The European AI Summit 2023. Zeit für einen Ausblick.
Lieber Gast,
morgen am Donnerstag, den 17. August, werde ich zum dritten Mal seit 2021 beim »Digital Demo Day 2023« im Areal Böhler in Düsseldorf zu Gast sein. Aus den beiden letzten Veranstaltungen konnte ich (a) eine Reihe von spannenden Inputs mitnehmen, (b) interessante Menschen sprechen, sehen und hören, und (c) neue Technologien live erleben. Zudem punktete die Veranstaltung mit hellen, freundlichen Hallen, einer Outdoor Area und einer netten Atmosphäre in einer bedeutsamen niederrheinischen Industriekultur.
Was erwartet uns auf dem DDD23 unter dem Motto »Celebrate the Future of Tech«? Ich habe mir für Sie (und mich), die Redner, das Programm und die Aussteller angeschaut.
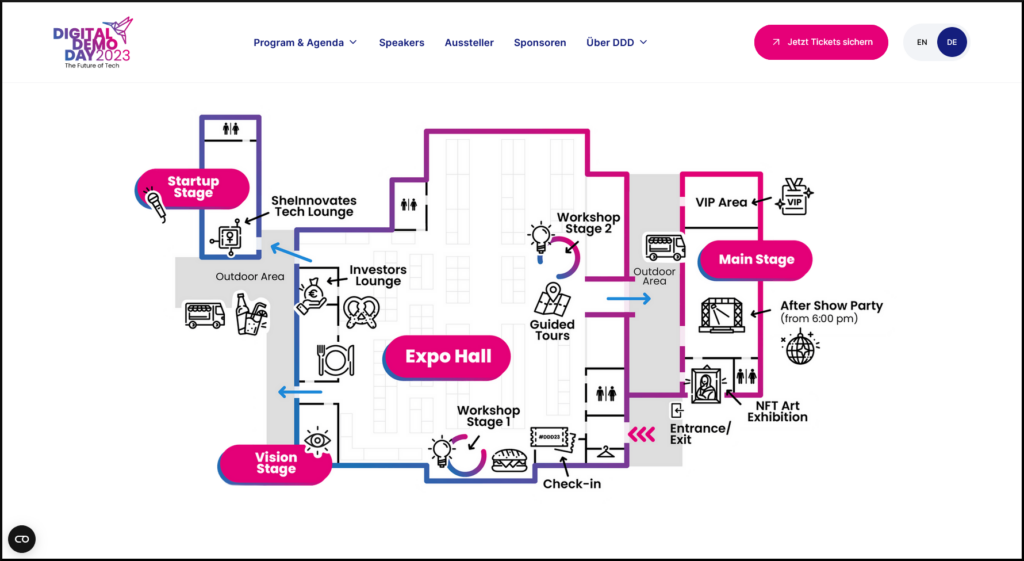
Zuerst jedoch einige Zahlen (natürlich!) von der Website: Demnach wird es fünf Bühnen geben mit mehr als 60 Rednern sowie mehr als 250 Ausstellern auf einer Fläche von 10.000 Quadratmetern. Die Veranstalter um Klemens Gaida und Peter Hornik vom Digital Innovation Hub Düsseldorf/Rheinland rechnen mit mehr als 4.500 Teilnehmern.
Hinweis: Alle Informationen und die Anmeldung zum Digital Demo Day 2023 gibt es auf dieser Website.
Redner
Beginnen wir mit den Speakern: Wer kommt? Einige prominente Namen lesen wir wie Gunter Dueck, Michael Groß, Mona Neubauer, Ana Ivanović, Tillman Schulz, Sara Nuru, Andreas Breitfeld, Mareike Awe und Amiaz Habtu als Main Stage Host.
Dazu gesellen sich u.a. aus Unternehmen und Start-Ups: Hanbing Ma (Head of Innovation & Digital Transformation der ERGO Group AG), Andrea Fernández Fonseca (Head of Data Intelligence bei trivago), Tero Ojanperä (Co-Founder & Chairman von Silo.AI), Mario Reis (Co-Founder & CEO von MONDAY.ROCKS), Edip Saliba als Sales Leader Data & AI von Microsoft, Holger Hoos (Professor for Artificial Intelligence & Co-Founder RWTH Aachen & Claire), Nardo Manaloto (Managing Partner, Qubits Ventures) und Tim Eschert von Fero Labs.
Aus Verbänden und Forschungseinrichtungen erleben wir zum Beispiel: Jörg Bienert vom KI Bundesverband e.V., Zahar Barth-Manzoori vom German Center for Research and Innovation (DWIH) San Francisco, Christian Temath (CEO von KI.NRW), Philipp Slusallek vom Deutsches Forschungszentrum für Künstliche Intelligenz, Ralf Schlindwein als Managing Director sowie David Strauch als Trend und Innovationscout bei der IHK Düsseldorf/Mettmann.

Auch die Politik und Verwaltung hat etwas zu sagen durch Menschen wie: Anna Christmann (Commissioner for Digital Economy & Start-ups, Federal Republic of Germany), Stephan Keller (Oberbürgermeister von Düsseldorf), Hans-Jürgen Petrauschke (Landrat des Rhein-Kreis Neuss), Pauline Kao (Generalkonsulin des U.S. Generalkonsulats Düsseldorf) und Theresa Winkels (Leiterin der Wirtschaftsförderung Düsseldorf).
Alle weiteren Redner finden sich auf der Website des Digital Demo Day 2023. Doch schauen wir uns nun dessen Programm an. Hinweis: Die Bilder in diesem Beitrag stammen, sofern nichts anderes angeben ist, vom Digital Demo Day 2022!
Programm
Die fünf Bühnen und ihr Fokus sind:
- Die Main Stage mit den Hauptthemen HealthTech, GreenTech und DeepTech NRW.
- Die Start-up Stage für innovative Entrepreneure und einem Live-Pitch (für ausgewählte Start-up Aussteller)
- Die Workshop Stage mit Branchenexperten und -innen mit Themen wie IoT, Innovationsplattformen, Weibliches Unternehmertum, Digitalisierung und Nachhaltigkeit.
- Die Vision Stage für auftauchende Trends in Technologie und Künstlicher Intelligenz. Mit einem Speed-Dating für Start-Ups und kleine bzw. mittlere Unternehmen unterstützt von der IHK Düsseldorf/Mettmann. Und: Nachmittags findet hier der European AI Summit statt mit 15 Rednern aus Praxis bis Forschung (Hinweis: Hier ist auch eine Online-Teilnahme über Zoom möglich).
Der Ablauf des Programms beginnt um 10.00 Uhr am 17. August 2023 auf der Hauptbühne mit einem Willkommensgruß von Klemens Gaida & Peter Hornik sowie von Stephan Keller und Hans-Jürgen Petrauschke.
Anschließend folgt die Keynote von Schwimm-Legende Michael Groß, der heute u.a. als Unternehmer, Redner und Trainer aktiv ist zu den Themen Change Management, Digital Leadership, Motivation und Talent Management. Für mich aus dem Human Resource Management und als Psychologe natürlich eine tolle Eröffnung des Tages! Zumal ich mich auch noch an die sportlichen Erfolge von Michael Groß erinnere.
Ab 10.30 Uhr starten die Referenten auf der Startup und Vision Stage. Eine weitere Keynote folgt ab 10.45 Uhr auf der Hauptbühne zur Künstlichen Intelligenz in der Medizin, während auf der Workshop Stage die Wirkung und Optionen von ChatGPT & OpenAI für Geschäftsmodelle diskutiert wird.
Weitere Höhepunkte aus meiner Sicht sind danach: Kommerzielle Drohnenflüge, Biohacking, die Keynote von Gunter Dueck um 12 Uhr, Data Products, das Panel “AI made in NRW”, der Workshop “How Fressnapf Validates Innovations”, AI for Team Leaders, ab 16.30 der European AI Summit sowie der finale Pitch auf der Startup Stage. Und: die NFT Art Exhibition mit tollen digitalen Kunstwerken (die ich schon letztes Jahr bestaunte).
Ab 18.00 Uhr wird als Abschluss des DDD23 die Aftershow Party starten – ein tolle Möglichkeit, den Tag entspannt bei einem Drink und netten Gespräche ausklingen zu lassen.
Aussteller
Über 250 deutsche und internationale Aussteller machen mit auf dem Digital Demo Day 2023. Vor allem Start-Ups aus dem Techbereich wie 1KOMMA5° (energy platform), aconno GmbH (IoT), Deepler (Software für die kollektive Intelligenz der Beschäftigten) DeepSkill (EdTech platform), MONDAY.ROCKS (Leadership App), One Data (AI-powered Data Product Builder) oder Weltenmacher (VR, AR, XR Technology).
Hinzu kommen Aussteller aus Unternehmen, Hubs und Inkubatoren, Universitäten, Internationalen Delegationen und öffentlichen Organisationen und internationale Start-up Booster. Die ganze Aussteller-Liste gibt es hier.
Fazit
Wie mein Ausblick zeigt, gibt es auf dem Digital Demo Day 2023 wieder eine Reihe von spannenden Inhalten, Menschen und Formaten. Meine Vorfreude steigt beim Schreiben dieser Zeilen – Besonders, da wir alle kürzlich und meist erstmals erfahren haben, dass persönliche Treffen auch verboten sein oder nur unter sehr starken Einschränkungen stattfinden können. Daher sind solche Veranstaltungen des Austausches natürlich noch wichtiger.

Ich bin morgen dabei. Sie bzw. Du auch? Dann freut mich Deine/Ihre Kontaktaufnahme am besten über meinem LinkedIn-Profil für einen persönlichen Austausch.
Alles Gut und herzliche Grüße!
Stefan Klemens
Lust auf einen Austausch zu People Analytics, Digital Assessment oder Künstliche Intelligenz im HRM? Dann vernetzen, Nachricht schreiben und / oder Termin für ein Online-Meeting vereinbaren. Oder klassisch: Telefonieren.
Titelfoto: Stefan Klemens




